
Alin Andersen
4237 字
21 分钟
C++20-P1_标准库多线程设施简介
封面来源:多线程
- 对多线程编程中的问题与相关C++工具进行解释,基于C++20.
多线程中的问题
- 数据竞争:多个线程访问共享内存,且至少有一个线程写入共享内存.(典型问题有撕裂读写,解决方案为设计只读数据结构,无写入时不会有竞争问题)
- 死锁:两个线程分别持有对方期望拥有的资源,导致共同阻塞.(解决方案:定时检测)
- 伪共享
line被一个线程锁定,另一线程无法并行(解决方案:内存对齐)
线程基础
创建线程
- 常用std::thread或std::jthread创建线程.
- 线程结合
- 除非对std::thread创建的线程使用.join()或者.detach()成员函数,线程默认是可结合的.
- 如果销毁可结合线程,C++会调用std::terminate()强行终止整个程序.
- jthread通过在析构函数中调用.join()避免了带崩整个程序的现象,但可能导致意外的阻塞.
#include <thread>// 1.std::thread// 允许接受任意数量的参数,第一个参数为待调用的函数,后续参数是向该函数传递的参数// 使用普通函数创建线程void counter(int id, int numIter) { for (auto i{0}; i < numIter; ++i) { cout << "Counter " << id << "has value " << i << endl; }}thread t1 {counter, 1, 6};thread t2 {counter, 2, 4};t1.join();t2.join();
// 使用functor创建线程struct Counter { public: explicit Counter(int id ,int numIter) : id_(id), max_iter_(numIter) {} void operator() () const { for (auto i{0}; i < numIter; ++i) cout << "Counter " << id << "has value " << i << endl; } private: int id_; int max_iter_;}thread t3 {Counter{1, 20}};auto c = Counter{2, 12};thread t4 {c};
// 使用lambda函数创建线程int id = 1;int numIter = 5;auto func = [id, numIter] () { for (auto i{0}; i < numIter; ++i) cout << "Counter " << id << "has value " << i << endl;};thread t5 {func};
// 使用类成员函数创建线程class ClassWithMemberCount { public: explicit ClassWithMemberCount(int id ,int numIter) : id_(id), max_iter_(numIter) {} void count(int id ,int numIter) { for (auto i{0}; i < numIter; ++i) cout << "Counter " << id << "has value " << i << endl; } private: int id_; int max_iter_;};ClassWithMemberCount cls{1, 2};thread t6 {&ClassWithMemberCount::count, &cls};
// 2.std::jthread// 类似于std::thread,支持上述所有操作.// 但在析构函数中自动调用.join()防止带崩整个程序,且支持协作式取消.// 协作式取消见"线程基础操作".线程基础操作
从线程获取计算结果
- 使用**指针或std::ref()**传递引用
- 使用promise-future组合(见后文)
#include <thread>// 1. 传递引用void adder(int &in) { ++in;}
int main() { int a{1}; std::thread(adder, a); // 会编译错误 std::thread(adder, std::ref(a)); // 正确 std::cout << a; // 2}
// 2. promise-future(见后文)异常处理
// 1. 传统异常处理// 适用于包装现有代码.exception_ptr current_exception() noexcept; // 返回正在处理的异常或者空的exception_ptr对象,可用if判断.[[noreturn]] void rethrow_exception(exception_ptr p); // 再次抛出正在处理的异常.exception_ptr make_exception_ptr(E e); // 复制一份e,创建一个指向副本的exception_ptr.
// 工作线程.void do_things() { // 实际工作. throw runtime_error {"Exception thrown!"};}
// Thread handling exceptionvoid ThreadFunc(exception_ptr& err) { try { do_things(); } catch (...) { err = current_exception(); // 使用引用将异常对象传递到上级. }}
// Class Managing Thread.void ThreadCreator() { exception_ptr error; thread t {ThreadFunc, ref(error)}; t.join(); if (error) { // 在主线程抛出异常. rethrow_exception(error); } else { // normal end. }}
int main() { try { ThreadCreator(); } catch (const exception& e) { // exception handler. }}
// 2.使用promise-future.// 更为简便,见promise-future一节.线程本地存储
thread_local int n;- 局部thread_local变量
- 在多次调用该函数时,将继承上一次的值(和static变量的行为一致)
- 但各个线程之间不共享,作用域仍为局部变量的作用域.
协作式取消
- 顾名思义,需要被取消线程协作的线程取消机制.
- 可由
std::jthread实现.
// thread 1: 需要被协作取消的线程.void f(std::stop_token stop_token, int value){ while (!stop_token.stop_requested()) { std::cout << value++ << ' ' << std::flush; std::this_thread::sleep_for(200ms); } std::cout << std::endl; // 析构时自动调用.join().}
int main(){ std::jthread thread(f, 5); // 打印 5 6 7 8... 约3s. std::this_thread::sleep_for(3s); // 析构时自动调用thread.request_stop(). // request_stop()函数也可以手动调用.}互斥类型
内存序
-
有时也被称为内存屏障.
-
现代CPU支持乱序执行,也即指令执行顺序与代码顺序并不一致.
- 单线程:不影响计算结果.
- 多线程:可能导致非预期结果.
-
因此,C++对很多原子操作支持指定内存序(规定了某个具体线程内的指令该怎样执行),以防止多线程时的非预期结果.
-
内存序种类 作用 memory_order_relaxed 不指定内存序. memory_order_consume(即将废弃) 用于读取指令.本线程上后续对该变量的读写操作禁止重排到该操作前. memory_order_acquire 用于读取指令.本线程上后续所有读写操作禁止重排到该操作前. memory_order_release 用于写入指令.前序所有读写操作禁止重排至该指令后. memory_order_acq_rel acquire + release memory_order_seq_cst acq_rel,所有使用seq_ast的指令有严格全序关系;大部分操作的默认值 -
release-acquire模型
atomic<int> aint{0};int nint{0}; // normal int.
void process1() { nint = 1; aint.store(1, std::memory_order_release);}
void process2() { int temp = aint.load(std::memory_order_acquire); if(temp == 1) assert(nint == 1); // release-acquire所保证的内容.}
// 注意:// 无论内存序如何,对atom变量的操作始终具有原子性.// release-acquire不能保证:// 1. acquire指令发生在release之后(这是由线程具体运行进度所决定).// 2. acquire指令先于release运行时,其它变量的有关行为.(如temp == 0时,nint的值存在竞争,可能为0也可能为1.)// release-acqure只能保证:// 当acquire指令确实发生在release之后时,release指令前的所有变量读写操作一定已经完成.原子类型/互斥量
- 对C++支持的原子类型/互斥量按开销进行排序如下.
| 开销排名 | 互斥类型 | 说明 |
|---|---|---|
| 1(最小) | std::atomic_flag | 最轻量的无锁原子标志位. |
| 2 | std::atomic<T> | 轻量原子操作类型 |
| 3 | 自旋锁 | 标准库未提供,需自行实现. |
| 4 | std::shared_mutex | 适用于多读者,读多写少的情况. |
| 5 | std::mutex | 标准阻塞式互斥锁. |
| 6 | std::recursive_mutex | 递归锁. |
| 7 | std::timed_mutex | 支持超时的标准锁. |
| 8(最大) | std::recursive_timed_mutex | 支持超时的递归锁. |
#include <atomic>// 1.std::atomic_flag// 1.1.初始化std::atomic_flag flag = ATOMIC_FLAG_INIT; // 初始化为clear(false)状态.std::atomic_flag flag2; // 不定状态(C++20后为clear状态).// 1.2.读写操作flag.clear(mem_order); // 置false.flag.test(mem_order); // 返回现有值.flag.test_and_set(mem_order); // 返回现有值,并置true.// 1.3.同步操作flag.wait(status, mem_order); // 阻塞到flag的值不等于status,且线程被唤醒(见"条件变量"一节).flag.notify_one(); // 唤醒单个线程(见"条件变量"一节).flag.notify_all(); // 唤醒所有线程(见"条件变量"一节).
// 2.std::atomic<T>// T必须不含cv限定,可以平凡拷贝,且具备四个移动/复制函数.// 2.1.初始化操作std::atomic<int> aint{0};std::atomic<int> aint1 = 0;// 2.2.读写操作aint = 1; // 等价于aint.store(1);aint.store(1, mem_order); // 写入值.aint.load(mem_order); // 读取值.int b = aint + 1; // 隐式转换到T.// 2.3.计算操作// 对整型变量,实现了fetch_add, _sub, _and位与, _or位或, _xor位异或, ++, --, +=, -=, &=, ^=, |=// 对浮点变量,实现了fetch_add, _subint fetched{value.fetch_add(4)}; // fetched == 10, value == 14.// 2.4.同步操作aint.wait(0, mem_order); // 类似于atomic_flag.aint.notify_one();aint.notify_all();// 2.5.其他操作aint.is_lock_free(); // 检查内部实现是否无锁.aint.exchange(1, mem_order); // 将1赋给aint,返回aint现有值.全过程为原子操作.aint.compare_exchange_weak(T&expected, T desired, mem_order); // 类似于_strong函数,性能更高,但有时aint == expected时,仍会返回false+更新expected.aint.compare_exchange_strong(T&expected, T desired, mem_order); // 原子CAS(compare and swap).// aint.compare_exchange_strong与如下原子逻辑等效:if (*this == expected) { *this = desired; return true;} else { expected = *this; return false;}// 2.6.别名std::atomic_int // atomic_*对所有默认scalar量都成立.// 2.7.原子引用atomic_ref// 将非原子变量临时包装为原子变量,性能较差.// 期间如果直接操作原变量,则原子性无法保证.int inc{0};atomic_ref<int> atomicCounter {counter};
// 3.自旋锁// C++不提供标准实现,需自己写.// 忙碌等待,只适合很短时间.atomic_flag spinlock = ATOMIC_FLAG_INIT;void lock() { while(spinlock.test_and_set(std::memory_order_acquire));}void unlock() { spinlock.clear(std::memory_order_release);}
// 4.mutex/shared_mutex/timed_mutex// 4.1.初始化std::mutex mut;// 4.2.加解锁mut.lock(); // 阻塞加锁.mut.try_lock(); // 非阻塞加锁,返回是否成功获得锁.mut.unlock(); // 释放锁.// 4.3.shared_mutex// 又被称为readerwriter锁,适合读多写少的情况.std::shared_mutex smut;// 写锁相关:独占,只有没有任何线程持有读锁/写锁时才能获得.smut.lock();smut.try_lock();smut.unlock();// 读锁相关:非独占,多个线程可同时持有读锁.smut.lock_shared();smut.try_lock_shared();smut.unlock_shared();// 4.4.recursive_mutex// 持有锁的线程可以多次加锁.// 注意:unlock()次数必须与lock()一致才能解开.std::recursive_mutex rmut;rmut.lock();rmut.try_lock();rmut.unlock();// 4.5.timed_mutexstd::timed_mutex tmut;std::recursive_timed_mutex rtmut;std::shared_timed_mutex stmut;tmut.try_lock_for(rel_time); // 在相对时间内尝试获得锁,返回是否成功的bool.tmut.try_lock_until(abs_time); // 在绝对时间点前尝试获得锁.互斥量智能管理
- 使用标准库提供的互斥量管理工具以避免忘记手动加解锁.
// 1.std::lock()与std::try_lock()// 适用于需要同时获得多个锁的情况,避免死锁.std::mutex mut1, mut2;std::lock(mut1, mut2, ...); // 不按指定顺序锁定互斥体对象;如果其中一个抛出异常,释放所有已获得的锁.std::try_lock(mut1, mut2, ...); // 全成功:返回-1; 失败:释放所有已获得的锁,返回未成功获得锁的序号(0开始).// 2.std::scoped_lockstd::scoped_lock slock(mut1, mut2, ...); // 使用std::lock()获取多个锁,在其生命周期结束自动释放.// 3.lockguardstd::mutex mut, mut2;std::lock_guard lock(mut); // 阻塞获得锁,在作用域生命周期结束时释放锁.mut2.lock();std::lock_guard lock2(mut2, std::adopt_lock); // 将已经获得的mut2交给lock2管理.// 4.unique_lockstd::timed_mutex tmut;std::unique_lock ulock(mut); // 初始化并阻塞获得锁,在作用域结束释放锁.std::unique_lock ulock(mut, std::defer_lock); // 初始化但不取得锁.std::unique_lock ulock(mut, std::try_to_lock); // 初始化并获得锁(非阻塞),可能不会成功获得锁.std::unique_lock ulock(mut, std::adopt_lock); // 将已经获得的mut交由ulock管理.std::unique_lock ulock(tmut, rel_time); // 必须使用支持超时的锁对象.std::unique_lock ulock(tmut, abs_time);bool is_obtained = ulock; // 判断锁是否成功获得.ulock.release(); // 释放对内部锁的所有权(不对其进行解锁).// 支持.lock(), .try_lock(), .unlock()等方法.// 在作用域结束会自动解锁.// 5.shared_lock// 类似于unique_lock,除了获取的是shared_mutex的读锁.线程同步
- 除了互斥类型,C++还支持了多种线程同步操作.
单次运行 call_once
- 保证特定函数在多线程中只运行一次.
- 适用于懒初始化相关工作.
std::once_flag flag;
void process() { std::call_once(flag, InitFunction); // 在多个线程同时运行process,只会运行一次InitFunction.}同步流
#include <syncstream>// 同步流中的内容在刷新缓冲区/析构时统一输出.// 每个线程有独立缓冲区,不会出现覆盖现象.std::osyncstream syncedCout {std::cout}; // 用于charstd::wosyncstream wsyncedCout; // 用于wchar条件变量
- 非忙碌等待.
- 运行到给定指令时,释放锁并挂起;被唤醒时尝试获得锁并继续执行.
- 存在虚假唤醒问题,故一般会额外提供一个谓词函数/flag变量,只有唤醒+对应变量满足一定条件才会结束等待.
// 1.用于atomic变量的条件变量 (C++20)// x.wait(oldValue)// 在X等于oldValue时,将持续阻塞;// 其它线程使用notify_one/notify_all/发生唤醒时,将检测X是否等于oldValue;// 若等于则继续阻塞,否则结束阻塞,线程继续执行.int main() { std::atomic_int aint{0}; std::thread job { [&aint] () { std::cout << "Job thread waiting." << std::endl; aint.wait(0); std::cout << aint << std::endl; }};
std::this_thread::sleep_for(std::chrono::seconds(1));std::cout << "Notify1" << std::endl;aint.notify_one(); // 子线程被唤醒,但aint仍为0,因此重新挂起,继续等待.std::this_thread::sleep_for(std::chrono::milliseconds(10)); // statement 1aint.store(1);std::this_thread::sleep_for(std::chrono::milliseconds(10)); // statement 2aint.notify_all(); // 子线程被唤醒,但aint仍为0,因此重新挂起,继续等待.std::cout << "Notify2" << std::endl;job.detach();}// 运行结果// Job thread waiting.// Notify1// Notify2 (与下一行顺序不定)// 1
// 2.用于mutex的环境变量.std::condition_variable cv; // 只能等待std::mutex的条件变量.std::condition_variable_any cva; // 可以等待多种锁类型(如shared_lock),但效率较低.cv.wait(mut); // 注意:调用前,该线程应该已经持有mut;将释放mut并在原地阻塞.cv.wait_until(mut, abs_time);cv.wait_for(mut, rel_time);cv.wait(mut, pred); // 带一个谓词的版本,当唤醒时,先获得锁,再检查谓词;如果为假,释放锁并再次进入等待.cv.notify_one();cv.notify_all();// 对于以下函数,lck应该已经获得.// 线程退出时将自动调用lck.unlock(); cond.notify_all();// 其它线程上的cond在等待的互斥量必须与lck.mutex()一致,否则UB.std::notify_all_at_thread_exit(cond, lck);
void producer() { // 准备数据... { std::unique_lock<std::mutex> lock{mut}; queue.push_back(new_data); } cout << "data ready."; cv.notify_one();}
void consumer() { std::unique_lock<std::mutex> lock{mut}; for(;;) { cv.wait(lock, [this]{return !queue.empty();}); // 处理数据... }}latch
- 一次性使用的线程协调点.
- 用正整数初始化,当其计数器清零时,释放所有阻塞在当前latch的线程.
- 适用于初始化场景.
#include <latch>std::latch latch{n};latch.arrive_and_wait(); // 递减计数器,阻塞当前线程.latch.wait(); // 不递减计数器,阻塞线程.latch.try_wait(); // 检测计数器是否已经为0.latch.countdown(); // 减少计数器(不阻塞).
// 示例程序std::latch latch{1};vector<jthread> threads;for(auto i = 0; i < 10; ++i) { threads.push_back(jthread{[&latch](){ // 运行slave线程初始化操作... latch.wait(); // 统一阻塞在latch处. // 正式的处理过程... }});}// master线程加载数据...latch.countdown(); // 递减latch计数器,开始运行slave线程.barrier
- 可重复使用的线程协调点.
- 给定数量的线程达到指定协调点时,执行结束回调.
- 结束回调执行完成后,结束所有进程的阻塞.
#include <barrier>void completionFunction() noexcept {...}int main() { const size_t kNThreads = 4u; barrier barrierPoint{kThreads, conpletionFunction}; vector<jthread> threads;
for(int i{0}; i < kNThreads; ++i) { threads.push_back(jthread{ [&barrierPoint](std::stop_token token){ while(!token.stop_requested()) { // 进行计算... barrierPoint.arrive_and_wait(); } } }); }}信号量 semaphore
- 轻量级同步源.
#include <semaphore>std::counting_semaphore cs{4}; // 多槽信号量std::binary_semaphore bs;
cs.acquire(); // 递减计数器,若计数器为0时阻塞,直到有其他线程释放.cs.try_acquire(); // 非阻塞获取信号量,未获得时返回false.cs.try_acquire_for(); // 在一定时间内尝试获取.cs.try_acquire_until();cs.release(); // 释放信号量.promise-future
- 方便地进行线程返回值获取与异常转移.
- 子线程将结果放入promise,父线程通过future获取返回结果.
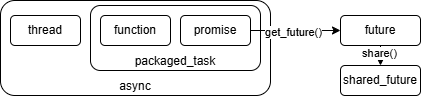
// 1. promise-future组合// promise不可复制,但可移动.promise<T> p;p.get_future(); // 获取对应的future,只允许调用一次.p.set_value(); // 设定返回值类型,只允许调用一次.p.set_value_at_thread_exit();p.set_exception();p.set_exception_at_thread_exit();
auto f{p.get_future()}; // f类型为future<T>f.get(); // 从future获取返回值,只能调用一次,否则抛异常.如果结果不可用会阻塞.f.valid(); // 检查future是否为共享态,只有共享态才能调用get();调用get()后会退出共享态.f.wait(); // 阻塞到结果可用.f.wait_for(); // 阻塞到结果可用/达到给定时间.f.wait_until();
void WorkFunction(promise<int> p) { // 实际计算... p.set_value(42);}
int main() { promise<int> p; auto f {p.get_future()}; jthread t{workFunction, move(p)};
while(f.wait_for(0)) { // 检查结果是否计算完成. auto res {f.get()}; cout << res; } else { // 执行结果未完成时的内容... }}
// 2. packaged_task// 进一步封装,无需手动传递promise.// 工作函数结束时,自动调用promise.set_value(return_of_work_function).// 同样不可复制,只能移动.int main() { pacakaged_task<int(void)> pt {[](){return 42;}}; auto f {pt.get_future()}; jthread t{move(pt)};
while(f.wait_for(0)) { // 检查结果是否计算完成. auto res {f.get()}; cout << res; } else { // 执行结果未完成时的内容... }}
// 3. async// 进一步封装,无需手动创建进程.// 注意:未捕获async返回值时,其返回的future临时对象将立即析构,// 因此会使父线程阻塞直到子线程完成.int workFunction() {return 42};int main() { // launch::async:强制创建新线程运行 // launch::deferred:强制在get()时使用当前进程运行 // launch::async | launch::deferred:自动选择(默认行为) auto f {async(launch::async, workFunction)};
while(f.wait_for(0)) { // 检查结果是否计算完成. auto res {f.get()}; cout << res; } else { // 执行结果未完成时的内容... }}
// 4. shared_future// 允许多个进程同时阻塞在get()函数.// 返回类型T必须可以复制.promise<T> p;shared_future<T> sf{p.get_future()}; // 该初始化只接受右值对象.sf.valid(); // 在get()后不会进入非共享态,因此结果可以由多个线程取得.
// 可起到类似于条件变量的作用.int main(){ std::promise<void> ready_promise, t1_ready_promise, t2_ready_promise; std::shared_future<void> ready_future(ready_promise.get_future());
std::chrono::time_point<std::chrono::high_resolution_clock> start;
auto fun1 = [&, ready_future]() -> std::chrono::duration<double, std::milli> { t1_ready_promise.set_value(); ready_future.wait(); // waits for the signal from main() return std::chrono::high_resolution_clock::now() - start; };
auto fun2 = [&, ready_future]() -> std::chrono::duration<double, std::milli> { t2_ready_promise.set_value(); ready_future.wait(); // waits for the signal from main() return std::chrono::high_resolution_clock::now() - start; };
auto fut1 = t1_ready_promise.get_future(); auto fut2 = t2_ready_promise.get_future();
auto result1 = std::async(std::launch::async, fun1); auto result2 = std::async(std::launch::async, fun2);
// wait for the threads to become ready fut1.wait(); fut2.wait();
// the threads are ready, start the clock start = std::chrono::high_resolution_clock::now();
// signal the threads to go ready_promise.set_value();
std::cout << "Thread 1 received the signal " << result1.get().count() << " ms after start\n" << "Thread 2 received the signal " << result2.get().count() << " ms after start\n";}小结
线程池在下一期单独介绍.
C++20-P1_标准库多线程设施简介
https://www.lithium-hydroxide.space/posts/250808_cpp_thread/
© 2025 LiH. All Rights Reserved. /
RSS /
Sitemap
Powered by Astro & Fuwari
 京公网安备11011402054629号 &
京ICP备2025124450号-1
京公网安备11011402054629号 &
京ICP备2025124450号-1
Powered by Astro & Fuwari
京公网安备11011402054629号 &
京ICP备2025124450号-1